Adversarial examples attack deep neural networks (DNNs) by providing small, undetectable perturbations of the input data that result in significantly different model outputs. There are two types of adversarial examples:
- White box attacks: attacker has access to neural network parameters and can backpropagate through the network
- Black box attacks: attacker does not have access to neural network parameters
This article will give detailed examples of each type of attack, their applications, and strategies for defending against these attacks.
Examples of white box attacks

Classic adversarial example from Goodfellow2014
How to find an adversarial example:
- Choose an image x from the testing set
- Define an adversary x’
- Propagate through the network, minimizing distance between x and x’ and/or magnitude of the adversarial noise (usually x’-x)
For example, Athalye et al. Synthesizing Robust Adversarial Examples. 2018 proposes a robust gradient technique that calculates the adversarial example using the infinity norm
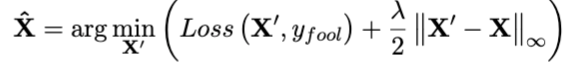
Fooling ResNet18 with learned noise, see my script
Common and historical gradient-based algorithms for defining adversarial images:
- Fast Gradient Sign Method (FGSM), see Goodfellow et al. Explaining and Harnessing Adversarial Examples. 2014
- Box-constrained LBFGS, see Carlini et al. Towards Evaluating the Robustness of Neural Networks. 2016
- Iterative FGSM, see Kurakin et al. Adversarial Machine Learning at Scale. 2017
Universal Adversarial Perturbations: Moosavi-Dezfooli et al. 2017 This attack uses a single perturbation vector that is image agnostic and generalizes well across neural network architectures.

Scaled perturbation vectors for different models trained on ImageNet
One Pixel Attack: Su et al. One Pixel Attack for Fooling Deep Neural Networks, 2019 This attack is more limited, where only one pixel is modified in the adversarial example. One pixel attacks are considered semi-black box since the algorithm it uses (differential evolution) only needs the probability of the labels and not the model’s entire set of parameters.
Single pixel (circled) attacks
Examples of black box attacks
Black box attacks can be harder to expertly deploy, but are still a considerable threat even with limited information.
In Ilyas et al. Black-box Adversarial Attacks with Limited Queries and Information. 2018, three threat models with query-limiting, partial-information setting, and label-only setting are proposed.

Example constrained black box attacks
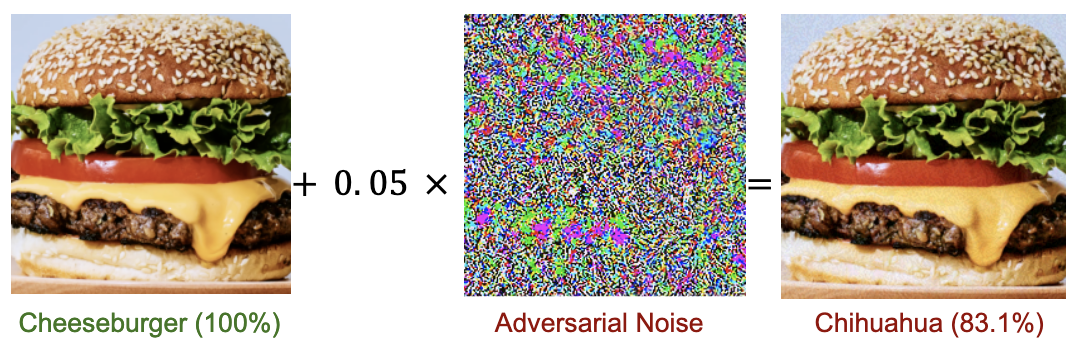
In Cheng et al. Improving Black-box Adversarial Attacks with a Transfer-based Prior. 2019 transfer-based priors and limited inference queries to the existing model lead to successful black box attacks.
Example attacks vs. number of queries
Security Implications
Adversarial attacks can be used to compromise the security of any real-world application of DNNs in several ways.
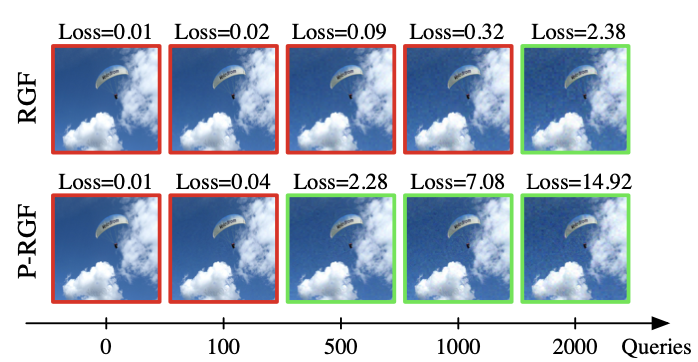
Physical endangerment: One of the most popular examples from Eykholt et al. Robust Physical-World Attacks on Deep Learning Models. 2018 incudes attaching physical perturbations to real world objects to trick machine learning systems. In their paper they attach stickers to stop signs that trick self-driving models into identifying the stop sign as a speed limit sign.
Dodging, Evasion, & Impersonation: Sharif et al’s A General Framework for Adversarial Examples with Objectives (2017) gives examples of how to design physical objects that can be used to thwart face detection and even impersonate other people.

Both images were classified by VGG10 as Brad Pitt
Fraud & scams: While computer vision is one of the most common areas of research for adversarial attacks, natural language processing has also been shown to be susceptible to these attacks. Consequences of these systems could be thwarting spam filters or influencing models used for credit scoring.
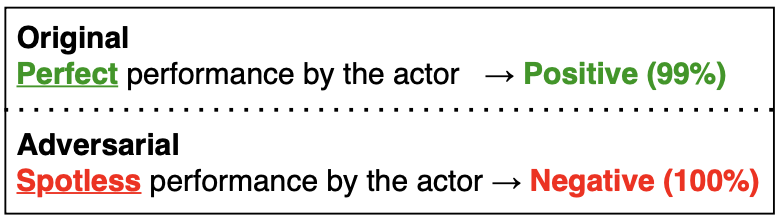
Example of text attack from Morris et al. TextAttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP. 2020
Model degradation: Adversarial attacks can be used to attack vulnerabilities of reinforcement learning and other online models to manipulate the models policy and inductive learning. The authors show the model’s degradation while learning Pong after being fed adversarial perturbations in Behzadan et al. Vulnerability of Deep Reinforcement Learning to Policy Induction Attacks. 2017
Defending against attacks
Prevent white box attacks: Using traditional model architectures (e.g. ResNet50) and widely popular training datasets (e.g. ImageNet) increase the probability that an attacker could launch a white box attack on your model, even if the model itself isn’t publicly available. Using custom and proprietary architectures and datasets can reduce the risk of a white box attack (although not a black box attack). Limiting inference calls and transparency of the model (e.g. probability values) can help reduce the risk of both types of adversarial attacks, as well as risk of model theft.
Data Transformations and Noise: Often, naive attacks are fragile to transformations. Simply applying minor transformations will defeat adversaries, although it’s highly dependent on how robust the attack is, models used, and intensity and type of the transformation.

Examples of transformations on adversary, see my script
Even if the adversary is defeated, adversarial examples will often decrease the model’s confidence and overall performance.
Improving model’s robustness: Ilyas et al. Adversarial Examples Are Not Bugs, They Are Features. 2019 argues adversarial examples can be directly attributed to the presence of non-robust features. By improving model’s robustness and reducing overfitting through various techniques (e.g. regularization, dropout, ensembling, network distillation, etc.), models may be less susceptible to naive attacks.
Adversarial training: Adversarial training includes using adversarial examples during the training process so that the trained model will be more robust to future adversarial attacks.
While adversarial training can be a quick patch to known attacks, adding adversaries into training can significantly increase training time and is really only reactionary and not adaptive. Adversarial training may not account for novel attacks, although using open-sourced libraries that do regular patches could increase adaptivity and robustness.
Read more: